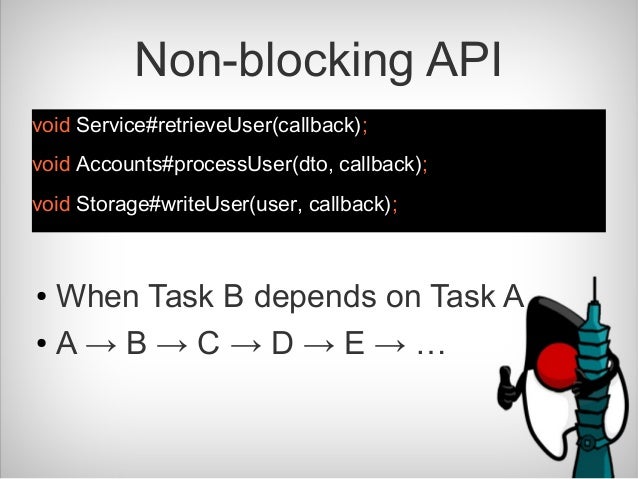
Asynchrnous calling is done previous in Java 7 by Future , But I think you don't want to use that if you have used that before. because it's blocking there.... So in Java 8, A more powerful utility class is invented to solve this problem. it's called
CompletableFuture.
Bad way to encapsulate : below is the traditional way to write the completableFurture(cf), it will wait and complete to save value into cf and it also will handle any exception in between the calling.But This code is too long and redundant...
public Future<Double> getPriceAsyncBad(String product) {
// create a cf,which will return the result later
CompletableFuture<Double> futurePrice = new CompletableFuture<>();
new Thread( () -> {
try {
double price = calculatePrice(product); // this function will sleep for 1 second
System.out.println("api call has finished");
futurePrice.complete(price); // return the value to cf after a long wait, cf stops
} catch (Exception ex) {
futurePrice.completeExceptionally(ex); // throw exception, and stop the cf
}
}).start(); // asynchronous computation
return futurePrice;
}
Good way to write : In java 8, there is a clean way to write. It has threadpool + exception + complete . All in one.
//new way ,CompletableFuture factory
public Future<Double> getPriceAsyncGood(String product) {
return CompletableFuture.supplyAsync(() -> calculatePrice(product));
}
Main Method :
public static void main(String[] args) {
Shopp shop = new Shopp("BestShop");
Future<Double> futurePrice = shop.getPriceAsyncGood("my favorite product");
System.out.println("Main Thread continue...");
try {
double price = futurePrice.get();
// conjested and waiting for future, like a semophore!! code can't continue
System.out.println(price);
} catch (Exception e) {}
}
Main Thread continue...
api call has finished
142.40742856631343
Alright , This is one small example showcasing a crawler fetching one product price asynchronously from one shop. what if it's from multiple shops . for example, I want to know what's the price of Iphone8 in different shops .
List<CompletableFuture<String>> priceFutures = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(
() -> String.format("%s price is %.2f", shop.getName(),
shop.getPrice(product))))
.collect(Collectors.toList());
But this return
List<CompletableFuture<String>> which is not what we want. we want List<String> ,join() will get the result from completableFuture == get(), the only difference is join() won't throw any exception.
public List<String> findPrices(String product) {
List<CompletableFuture<String>> priceFutures = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is " +
shop.getPrice(product)))
.collect(Collectors.toList());
return priceFutures.stream()
.map(CompletableFuture::join) //wait all processes to finish and get
.collect(toList());
}
Ok, It seems perfect for our application. because it fulltils our target. However if you do it in this way, it will be very slow. Becuase internally , its threadpool size is preconfigured commonly which is not optimised for different cases. So Let's configure our threadpool size to speed it up.
// optimised threadpool
// threadpool = the smaller between shop size and 100.
Executors.newFixedThreadPool(Math.min(shopp.size(), 100),
new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true); // use deamon, it won't hinder the application.
return t;
}
});
Use it
CompletableFuture.supplyAsync(() -> shop.getName() + " price is " +
shop.getPrice(product), executor);
Ok,Let's see an exmaple how CompletableFuture process a series of job flows using
thenApply() and
thenCompose() :
private final Executor executor = public List<String> findPrices(String product) {
List<CompletableFuture<String>> priceFutures = shops.stream()
// asyn to get price
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getPrice(product), executor))
.map(future -> future.thenApply(Quote::parse)) // parse the quote
.map(future -> future.thenCompose(quote ->
// first cf's result as second cf's input in thenCompose
CompletableFuture.supplyAsync(() -> Discount.applyDiscount(quote), executor)))
// asyn to apply quote
.collect(Collectors.toList());
return priceFutures.stream().map(CompletableFuture::join).collect(Collectors.toList());
}
you may notice, thenCompose will take the first cf's output as the second cf's input. in other word, these 2 cfs are linked and connected in sequence. So what if our 2 cfs has no relationship , so we purely want 2 unrelated thread to run . then we can use
thenCombine()
Future<Double> futurePriceInUSD =
CompletableFuture.supplyAsync(() -> shop.getPrice(product))
.thenCombine(
CompletableFuture.supplyAsync(
() -> exchangeService.getRate(Money.EUR, Money.USD)),
(price, rate) -> price * rate
);
Ok, Now, the requirement may change, you are crawlling prices from different websites. you want 2 scenarios one is when all is ready then return . one is any one has value to return , then return. so how to implement this 2 scenarios? we use
anyOf() and
allOf() , but we must convert into cf array first.
CompletableFuture[] futures = findPricesStream("myPhone") // convert into cf array .map(f -> f.thenAccept(System.out::println))
.toArray(size -> new CompletableFuture[size]);
// all threads of cf have return value . then join and return
CompletableFuture.allOf(futures).join();
// any threads of cf have return value . then join and return
CompletableFuture.anyOf(futures).join();
Ok, if your last cf have no return <Void>, and you still want to do some post processing like : printing. you can use
thenApply()
findPricesStream("myPhone").map(f -> f.thenAccept(System.out::println));
That's all.